 rauantodev
rauantodev 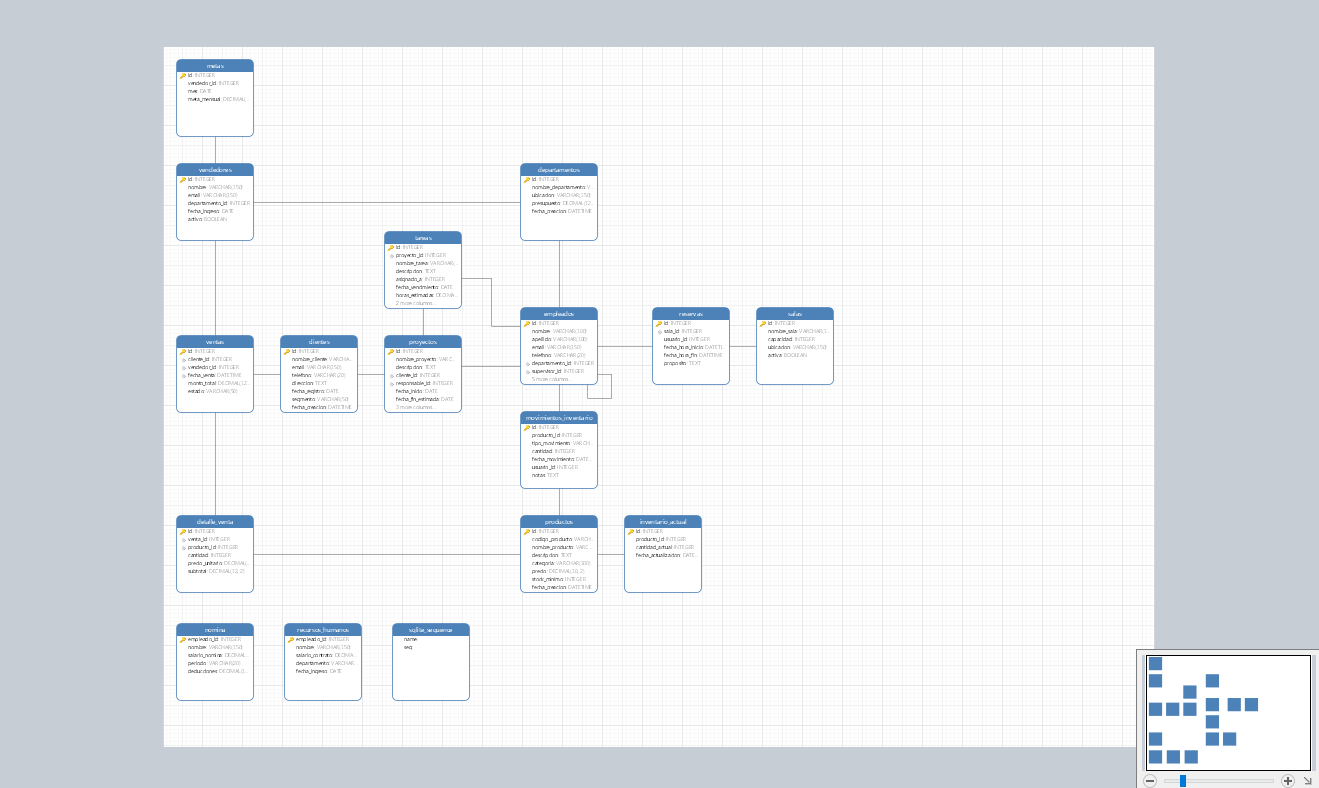
SQL JOINs
Los JOINs son una de las operaciones más poderosas en SQL.
raulanto
Desarrollador Full Stack
01 Oct 2025
23 min read
Guía Completa de SQL JOINs: De Básico a Avanzado
Los JOINs son una de las operaciones más poderosas en SQL, permitiéndonos combinar datos de múltiples tablas relacionadas. Dominar los diferentes tipos de JOIN es esencial para cualquier desarrollador que trabaje con bases de datos relacionales.
1. INNER JOIN
¿Qué hace?
Retorna únicamente los registros que tienen coincidencias en ambas tablas. Es como una intersección en teoría de conjuntos.
- Cuando necesitas solo los datos que existen en ambas tablas
- Para consultas donde la relación es obligatoria
- Cuando quieres filtrar automáticamente registros huérfanos
- Para reportes que solo incluyen datos completos
- Si necesitas ver registros sin relaciones
- Cuando los datos faltantes son importantes para el análisis
- En reportes de auditoría donde necesitas identificar registros incompletos
Preguntas que responde:
- "¿Qué empleados tienen un departamento asignado?"
- "¿Qué productos se han vendido?"
- "¿Qué proyectos tienen tareas asignadas?"
-- ¿Qué empleados trabajan en qué departamentos?
SELECT
e.nombre,
e.apellido,
e.puesto,
d.nombre_departamento,
d.ubicacion
FROM empleados e
INNER JOIN departamentos d ON e.departamento_id = d.id;
Resultado
| nombre | apellido | puesto | nombre_departamento | ubicacion |
|---|---|---|---|---|
| Juan | Pérez | Director de Tecnología | Tecnología | Edificio A - Piso 3 |
| María | González | Desarrollador Senior | Tecnología | Edificio A - Piso 3 |
| Carlos | Rodríguez | Gerente de Ventas | Ventas | Edificio B - Piso 1 |
| Ana | Martínez | Ejecutivo de Ventas | Ventas | Edificio B - Piso 1 |
| Luis | López | Jefe de Marketing | Marketing | Edificio B - Piso 2 |
departamento_id asignado.departamento_id, no aparece en el resultado.Ejemplo Complejo - Sistema de Gestión de Proyectos:
SELECT
p.nombre_proyecto,
p.fecha_inicio,
p.presupuesto,
c.nombre_cliente,
c.email AS email_cliente,
c.segmento,
e.nombre AS responsable,
e.email AS email_responsable,
d.nombre_departamento,
COUNT(DISTINCT t.id) AS total_tareas,
SUM(t.horas_estimadas) AS horas_totales,
AVG(t.progreso) AS progreso_promedio,
SUM(CASE WHEN t.estado = 'completada' THEN 1 ELSE 0 END) AS tareas_completadas
FROM proyectos p
INNER JOIN clientes c ON p.cliente_id = c.id
INNER JOIN empleados e ON p.responsable_id = e.id
INNER JOIN departamentos d ON e.departamento_id = d.id
INNER JOIN tareas t ON t.proyecto_id = p.id
WHERE p.estado = 'activo'
AND t.fecha_vencimiento >= DATE('now')
GROUP BY p.id, p.nombre_proyecto, p.fecha_inicio, p.presupuesto,
c.nombre_cliente, c.email, c.segmento,
e.nombre, e.email, d.nombre_departamento
HAVING AVG(t.progreso) < 75
ORDER BY progreso_promedio ASC;
- Proyectos activos con bajo progreso que necesitan atención
- Solo incluye proyectos que tienen cliente, responsable, departamento y tareas asignadas
- Útil para identificar proyectos en riesgo de incumplimiento
Resultado
| nombre_proyecto | fecha_inicio | presupuesto | nombre_cliente | email_cliente | segmento | responsable | email_responsable | nombre_departamento | total_tareas | horas_totales | progreso_promedio | tareas_completadas |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sistema de Gestión Empresarial | 2024-01-15 | 150000.00 | Corporativo ABC | contacto@abc.com | Premium | Juan | juan.perez@empresa.com | Tecnología | 7 | 620 | 61.42857142857143 | 2 |
| Campaña Marketing Digital Q2 | 2024-04-01 | 45000.00 | Comercial XYZ | ventas@xyz.com | Regular | Luis | luis.lopez@empresa.com | Marketing | 6 | 280 | 67.5 | 1 |
| Migración a la Nube | 2024-03-01 | 120000.00 | Tech Solutions | info@techsolutions.com | Premium | Juan | juan.perez@empresa.com | Tecnología | 8 | 470 | 57.5 | 2 |
| Aplicación Móvil E-commerce | 2024-02-15 | 85000.00 | Supermercados Unidos | compras@unidos.com | Premium | María | maria.gonzalez@empresa.com | Tecnología | 7 | 610 | 62.142857142857146 | 1 |
| Rediseño Portal Web | 2024-05-01 | 35000.00 | Empresa MNO | admin@mno.com | Premium | Carmen | carmen.ortiz@empresa.com | Tecnología | 7 | 380 | 50 | 1 |
2. LEFT JOIN (LEFT OUTER JOIN)
¿Qué hace?
Retorna todos los registros de la tabla izquierda y los registros coincidentes de la tabla derecha. Si no hay coincidencia, retorna NULL en las columnas de la tabla derecha.
- Cuando necesitas todos los registros de la tabla principal, independientemente de si tienen relaciones
- Para identificar registros sin relaciones (usando
WHERE columna_derecha IS NULL) - En reportes donde los datos faltantes son importantes
- Para análisis de cobertura o completitud de datos
- Si solo necesitas registros con relaciones completas (usa INNER JOIN)
- Cuando los datos sin relación no son relevantes para el análisis
- "¿Qué clientes no han realizado compras?"
- "¿Qué empleados no tienen departamento asignado?"
- "¿Qué productos nunca se han vendido?"
- "¿Cuál es el estado de TODOS mis clientes, incluso los inactivos?"
Ejemplo Básico:
-- Mostrar TODOS los empleados, tengan o no departamento
SELECT
e.nombre,
e.apellido,
e.puesto,
d.nombre_departamento,
CASE
WHEN d.id IS NULL THEN 'Sin Departamento'
ELSE 'Asignado'
END AS estado_asignacion
FROM empleados e
LEFT JOIN departamentos d ON e.departamento_id = d.id;
Resultado:
| nombre | apellido | puesto | nombre_departamento | estado_asignacion |
|---|---|---|---|---|
| Juan | Pérez | Director de Tecnología | Tecnología | Asignado |
| Carlos | Rodríguez | Gerente de Ventas | Ventas | Asignado |
| Luis | López | Jefe de Marketing | Marketing | Asignado |
| Patricia | Sánchez | Directora de RRHH | Recursos Humanos | Asignado |
| Roberto | Fernández | Director Financiero | Finanzas | Asignado |
| María | González | Desarrollador Senior | Tecnología | Asignado |
NULL en nombre_departamento).Ejemplo Complejo - Sistema de Análisis de Ventas:
SELECT
c.id,
c.nombre_cliente,
c.email,
c.fecha_registro,
c.segmento,
COUNT(DISTINCT v.id) AS total_ventas,
COALESCE(SUM(v.monto_total), 0) AS ingresos_totales,
COALESCE(AVG(v.monto_total), 0) AS ticket_promedio,
MAX(v.fecha_venta) AS ultima_compra,
CAST((julianday('now') - julianday(MAX(v.fecha_venta))) AS INTEGER) AS dias_sin_comprar,
CASE
WHEN COUNT(v.id) = 0 THEN 'Sin Compras'
WHEN (julianday('now') - julianday(MAX(v.fecha_venta))) > 90 THEN 'Inactivo'
WHEN (julianday('now') - julianday(MAX(v.fecha_venta))) > 30 THEN 'En Riesgo'
ELSE 'Activo'
END AS estado_cliente
FROM clientes c
LEFT JOIN ventas v ON c.id = v.cliente_id
AND v.fecha_venta >= DATE('now', '-1 year')
GROUP BY c.id, c.nombre_cliente, c.email, c.fecha_registro, c.segmento
ORDER BY ingresos_totales DESC;
Resultado
| id | nombre_cliente | fecha_registro | segmento | total_ventas | ingresos_totales | ticket_promedio | ultima_compra | dias_sin_comprar | estado_cliente | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Corporativo ABC | contacto@abc.com | 2023-01-10 | Premium | 0 | 0 | 0 | null | null | Sin Compras |
| 2 | Comercial XYZ | ventas@xyz.com | 2023-03-15 | Regular | 0 | 0 | 0 | null | null | Sin Compras |
| 3 | Tienda El Ahorro | info@elahorro.com | 2024-01-20 | Nuevo | 0 | 0 | 0 | null | null | Sin Compras |
- Estado de TODOS los clientes, incluso los que nunca han comprado
- Identifica clientes inactivos o en riesgo de abandonar
- Perfecto para campañas de reactivación o seguimiento comercial
Identificar registros huérfanos:
-- ¿Qué empleados NO tienen departamento asignado?
SELECT
e.id,
e.nombre,
e.apellido,
e.email,
e.fecha_contratacion
FROM empleados e
LEFT JOIN departamentos d ON e.departamento_id = d.id
WHERE d.id IS NULL;
3. RIGHT JOIN (RIGHT OUTER JOIN)
¿Qué hace?
Es el inverso del LEFT JOIN. Retorna todos los registros de la tabla derecha y los coincidentes de la izquierda.
¿Cuándo usarlo?
- Cuando la tabla principal está en el lado derecho de la consulta
- Para mantener la legibilidad en consultas con múltiples JOINs
- Cuando trabajas con código legacy que usa este patrón
¿Cuándo NO usarlo?
- En la mayoría de los casos (puedes usar LEFT JOIN invirtiendo las tablas)
- SQLite NO soporta RIGHT JOIN nativamente
Preguntas que responde:
- "¿Qué departamentos no tienen empleados?"
- "¿Qué productos en inventario no tienen movimientos?"
Ejemplo Básico:
-- Mostrar TODOS los departamentos, tengan o no empleados
-- (En SQLite, tendrías que usar LEFT JOIN invirtiendo las tablas)
SELECT
e.nombre,
e.apellido,
d.nombre_departamento,
d.ubicacion
FROM empleados e
RIGHT JOIN departamentos d ON e.departamento_id = d.id;
Nota: Esto es para sql lite:
SELECT
e.nombre,
e.apellido,
d.nombre_departamento,
d.ubicacion
FROM departamentos d
LEFT JOIN empleados e ON e.departamento_id = d.id;
Ejemplo Complejo - Sistema de Inventario:
SELECT
p.codigo_producto,
p.nombre_producto,
p.categoria,
p.stock_minimo,
COALESCE(i.cantidad_actual, 0) AS stock_actual,
COALESCE(SUM(m.cantidad), 0) AS movimientos_mes,
CASE
WHEN i.cantidad_actual IS NULL THEN 'Sin Inventario'
WHEN i.cantidad_actual < p.stock_minimo THEN 'Crítico'
WHEN i.cantidad_actual < p.stock_minimo * 2 THEN 'Bajo'
ELSE 'Óptimo'
END AS estado_inventario
FROM movimientos_inventario m
RIGHT JOIN productos p ON m.producto_id = p.id
AND m.fecha_movimiento >= DATE('now', '-1 month')
LEFT JOIN inventario_actual i ON p.id = i.producto_id
GROUP BY p.id, p.codigo_producto, p.nombre_producto, p.categoria, p.stock_minimo, i.cantidad_actual
HAVING estado_inventario IN ('Sin Inventario', 'Crítico', 'Bajo')
ORDER BY estado_inventario, p.categoria;
SQLite equivalente:
SELECT
p.codigo_producto,
p.nombre_producto,
p.categoria,
p.stock_minimo,
COALESCE(i.cantidad_actual, 0) AS stock_actual,
COALESCE(SUM(m.cantidad), 0) AS movimientos_mes,
CASE
WHEN i.cantidad_actual IS NULL THEN 'Sin Inventario'
WHEN i.cantidad_actual < p.stock_minimo THEN 'Crítico'
WHEN i.cantidad_actual < p.stock_minimo * 2 THEN 'Bajo'
ELSE 'Óptimo'
END AS estado_inventario
FROM productos p
LEFT JOIN movimientos_inventario m ON m.producto_id = p.id
AND m.fecha_movimiento >= DATE('now', '-1 month')
LEFT JOIN inventario_actual i ON p.id = i.producto_id
GROUP BY p.id, p.codigo_producto, p.nombre_producto, p.categoria, p.stock_minimo, i.cantidad_actual
HAVING estado_inventario IN ('Sin Inventario', 'Crítico', 'Bajo')
ORDER BY estado_inventario, p.categoria;
- TODOS los productos en el catálogo
- Identifica productos sin inventario o con stock crítico
- Útil para órdenes de compra y gestión de almacén
4. FULL OUTER JOIN
¿Qué hace?
Retorna todos los registros cuando hay una coincidencia en la tabla izquierda O derecha. Combina LEFT JOIN y RIGHT JOIN.
¿Cuándo usarlo?
- Análisis de discrepancias entre dos conjuntos de datos
- Reconciliación de registros entre sistemas
- Cuando necesitas ver TODO, independientemente de las relaciones
- Auditorías y validaciones de integridad de datos
¿Cuándo NO usarlo?
- SQLite NO soporta FULL OUTER JOIN nativamente (debe simularse)
- Cuando solo necesitas datos de un lado de la relación
Preguntas que responde:
- "¿Qué registros existen en el sistema A pero no en el sistema B, y viceversa?"
- "¿Dónde hay inconsistencias entre dos fuentes de datos?"
- "¿Qué empleados están en nómina pero no en RRHH, o al revés?"
Simulación en SQLite:
-- Empleados y departamentos: mostrar TODO
SELECT
e.nombre AS empleado,
d.nombre_departamento
FROM empleados e
LEFT JOIN departamentos d ON e.departamento_id = d.id
UNION
SELECT
e.nombre AS empleado,
d.nombre_departamento
FROM departamentos d
LEFT JOIN empleados e ON e.departamento_id = d.id;
Ejemplo Complejo - Reconciliación de Sistemas:
-- Sistema de nómina vs sistema de RRHH
SELECT
COALESCE(n.empleado_id, r.empleado_id) AS empleado_id,
COALESCE(n.nombre, r.nombre) AS nombre,
n.salario_nomina,
r.salario_contrato,
CASE
WHEN n.empleado_id IS NULL THEN 'Solo en RRHH'
WHEN r.empleado_id IS NULL THEN 'Solo en Nómina'
WHEN n.salario_nomina != r.salario_contrato THEN 'Discrepancia Salarial'
ELSE 'Correcto'
END AS estado_reconciliacion,
ABS(COALESCE(n.salario_nomina, 0) - COALESCE(r.salario_contrato, 0)) AS diferencia
FROM (
SELECT * FROM nomina
UNION ALL
SELECT NULL, NULL, NULL, NULL, NULL
WHERE NOT EXISTS (SELECT 1 FROM nomina)
) n
LEFT JOIN recursos_humanos r ON n.empleado_id = r.empleado_id
UNION
SELECT
COALESCE(n.empleado_id, r.empleado_id) AS empleado_id,
COALESCE(n.nombre, r.nombre) AS nombre,
n.salario_nomina,
r.salario_contrato,
CASE
WHEN n.empleado_id IS NULL THEN 'Solo en RRHH'
WHEN r.empleado_id IS NULL THEN 'Solo en Nómina'
WHEN n.salario_nomina != r.salario_contrato THEN 'Discrepancia Salarial'
ELSE 'Correcto'
END AS estado_reconciliacion,
ABS(COALESCE(n.salario_nomina, 0) - COALESCE(r.salario_contrato, 0)) AS diferencia
FROM recursos_humanos r
LEFT JOIN nomina n ON n.empleado_id = r.empleado_id
WHERE estado_reconciliacion != 'Correcto'
ORDER BY estado_reconciliacion, diferencia DESC;
- Empleados que están solo en uno de los sistemas
- Inconsistencias salariales entre nómina y contratos
- Errores críticos que requieren corrección inmediata
5. CROSS JOIN
¿Qué hace?
Produce el producto cartesiano de ambas tablas, es decir, combina cada fila de la primera tabla con cada fila de la segunda tabla.
¿Cuándo usarlo?
- Generar combinaciones de datos (productos con colores/tallas)
- Crear matrices o grillas de datos (calendarios, horarios)
- Inicializar tablas de configuración
- Análisis combinatorio
¿Cuándo NO usarlo?
- Con tablas grandes (puede generar millones de registros)
- Cuando necesitas relaciones específicas entre registros
- Sin filtros adicionales (puede consumir mucha memoria)
Preguntas que responde:
- "¿Qué combinaciones de productos puedo crear?"
- "¿Qué horarios disponibles tengo en todas mis salas?"
- "¿Cuáles son todas las posibles asignaciones de empleados a proyectos?"
Ejemplo Básico:
-- Generar todas las combinaciones de tallas y colores
SELECT
t.talla,
c.color,
t.talla || '-' || c.color AS sku
FROM (
SELECT 'S' AS talla UNION ALL
SELECT 'M' UNION ALL
SELECT 'L' UNION ALL
SELECT 'XL'
) t
CROSS JOIN (
SELECT 'Rojo' AS color UNION ALL
SELECT 'Azul' UNION ALL
SELECT 'Verde' UNION ALL
SELECT 'Negro'
) c
ORDER BY t.talla, c.color;
Resultado: 16 combinaciones (4 tallas × 4 colores)
Ejemplo Complejo - Sistema de Horarios de Reservas:
-- Generar matriz de disponibilidad completa para reservas
WITH dias_calendario AS (
-- Generar próximos 30 días
WITH RECURSIVE cnt(x) AS (
SELECT 0
UNION ALL
SELECT x+1 FROM cnt
LIMIT 30
)
SELECT
DATE('now', '+' || x || ' days') AS fecha,
CASE
WHEN CAST(strftime('%w', DATE('now', '+' || x || ' days')) AS INTEGER) IN (0, 6)
THEN 1 ELSE 0
END AS es_fin_semana
FROM cnt
),
bloques_horario AS (
SELECT '08:00' AS hora_inicio, '09:00' AS hora_fin UNION ALL
SELECT '09:00', '10:00' UNION ALL
SELECT '10:00', '11:00' UNION ALL
SELECT '11:00', '12:00' UNION ALL
SELECT '14:00', '15:00' UNION ALL
SELECT '15:00', '16:00' UNION ALL
SELECT '16:00', '17:00' UNION ALL
SELECT '17:00', '18:00'
)
SELECT
s.nombre_sala,
s.capacidad,
d.fecha,
h.hora_inicio,
h.hora_fin,
d.fecha || ' ' || h.hora_inicio AS fecha_hora_inicio_completa,
d.fecha || ' ' || h.hora_fin AS fecha_hora_fin_completa,
COALESCE(r.id, 0) AS reserva_id,
COALESCE(r.proposito, '') AS proposito_reserva,
CASE
WHEN r.id IS NOT NULL THEN 'Ocupado'
WHEN d.fecha < DATE('now') THEN 'Pasado'
WHEN d.es_fin_semana = 1 THEN 'No Disponible'
ELSE 'Disponible'
END AS estado,
CASE
WHEN r.id IS NOT NULL THEN '#EF4444' -- Rojo
WHEN d.es_fin_semana = 1 THEN '#9CA3AF' -- Gris
ELSE '#10B981' -- Verde
END AS color_estado
FROM salas s
CROSS JOIN dias_calendario d
CROSS JOIN bloques_horario h
LEFT JOIN reservas r ON s.id = r.sala_id
AND DATE(r.fecha_hora_inicio) = d.fecha
AND TIME(r.fecha_hora_inicio) = h.hora_inicio
WHERE s.activa = 1
AND d.fecha >= DATE('now')
ORDER BY s.nombre_sala, d.fecha, h.hora_inicio;
¿Qué responde esta consulta?
- Matriz completa de disponibilidad: salas × días × horarios
- Identifica espacios disponibles y ocupados
- Perfecto para sistemas de reserva con vista de calendario
- Genera 240 combinaciones por sala (30 días × 8 bloques horarios)
Ejemplo - Generador de Catálogo de Productos:
-- Crear todas las variantes de producto
SELECT
p.nombre_producto,
t.talla,
c.color,
p.precio AS precio_base,
p.precio + t.ajuste_precio + c.ajuste_precio AS precio_final,
p.codigo_producto || '-' || t.codigo || '-' || c.codigo AS sku_completo
FROM (
SELECT
'Camiseta Básica' AS nombre_producto,
'CAM-001' AS codigo_producto,
25.00 AS precio
) p
CROSS JOIN (
SELECT 'XS' AS talla, 'XS' AS codigo, -2.00 AS ajuste_precio UNION ALL
SELECT 'S', 'S', 0.00 UNION ALL
SELECT 'M', 'M', 0.00 UNION ALL
SELECT 'L', 'L', 0.00 UNION ALL
SELECT 'XL', 'XL', 3.00 UNION ALL
SELECT 'XXL', 'XXL', 5.00
) t
CROSS JOIN (
SELECT 'Blanco' AS color, 'BLN' AS codigo, 0.00 AS ajuste_precio UNION ALL
SELECT 'Negro', 'NEG', 1.00 UNION ALL
SELECT 'Azul', 'AZL', 1.00 UNION ALL
SELECT 'Rojo', 'ROJ', 1.50 UNION ALL
SELECT 'Verde', 'VRD', 1.50
) c;
Resultado: 30 variantes de producto (6 tallas × 5 colores) con SKUs únicos y precios ajustados.
6. SELF JOIN
¿Qué hace?
Une una tabla consigo misma. Útil para datos jerárquicos o relaciones dentro de la misma tabla.
¿Cuándo usarlo?
- Estructuras jerárquicas (empleados y supervisores)
- Comparaciones entre registros de la misma tabla
- Encontrar relaciones o patrones dentro de los datos
- Análisis de redes o grafos
¿Cuándo NO usarlo?
- Cuando la relación es entre tablas diferentes
- Si puedes resolver el problema sin duplicar la tabla (consume más recursos)
Preguntas que responde:
- "¿Quién es el supervisor de cada empleado?"
- "¿Qué empleados ganan más que su supervisor?"
- "¿Qué clientes tienen el mismo email o teléfono (duplicados)?"
- "¿Qué productos se han vendido juntos frecuentemente?"
Ejemplo Básico - Jerarquía de Empleados:
-- ¿Quién reporta a quién?
SELECT
e.nombre || ' ' || e.apellido AS empleado,
e.puesto AS puesto_empleado,
e.salario AS salario_empleado,
s.nombre || ' ' || s.apellido AS supervisor,
s.puesto AS puesto_supervisor
FROM empleados e
LEFT JOIN empleados s ON e.supervisor_id = s.id
WHERE e.activo = 1
ORDER BY s.nombre, e.nombre;
Ejemplo Complejo - Estructura Organizacional Completa:
WITH RECURSIVE jerarquia AS (
-- Nivel 0: Empleados sin supervisor (dirección)
SELECT
e.id,
e.nombre || ' ' || e.apellido AS nombre_completo,
e.puesto,
e.salario,
e.supervisor_id,
0 AS nivel,
e.nombre || ' ' || e.apellido AS ruta_jerarquica
FROM empleados e
WHERE e.supervisor_id IS NULL AND e.activo = 1
UNION ALL
-- Niveles subsecuentes
SELECT
e.id,
e.nombre || ' ' || e.apellido,
e.puesto,
e.salario,
e.supervisor_id,
j.nivel + 1,
j.ruta_jerarquica || ' > ' || e.nombre || ' ' || e.apellido
FROM empleados e
INNER JOIN jerarquia j ON e.supervisor_id = j.id
WHERE e.activo = 1
)
SELECT
j.nivel,
SUBSTR(' ', 1, j.nivel * 2) || j.nombre_completo AS empleado_indentado,
j.puesto,
j.salario,
s.nombre_completo AS supervisor_directo,
d.nombre_departamento,
j.ruta_jerarquica AS cadena_mando,
-- Análisis salarial
COALESCE(s.salario, 0) AS salario_supervisor,
CASE
WHEN j.nivel = 0 THEN 'Dirección'
WHEN j.salario >= s.salario THEN ' Revisión Necesaria'
WHEN (j.salario * 1.0 / NULLIF(s.salario, 0)) > 0.85 THEN 'Cercano a Supervisor'
ELSE 'Normal'
END AS analisis_salarial,
-- Contar subordinados directos
(SELECT COUNT(*) FROM empleados e2 WHERE e2.supervisor_id = j.id AND e2.activo = 1) AS subordinados_directos
FROM jerarquia j
LEFT JOIN jerarquia s ON j.supervisor_id = s.id
LEFT JOIN empleados e ON j.id = e.id
LEFT JOIN departamentos d ON e.departamento_id = d.id
ORDER BY j.nivel, j.nombre_completo;
¿Qué responde esta consulta?
- Estructura organizacional completa con niveles
- Identifica anomalías salariales
- Muestra cadena de mando para cada empleado
- Cuenta subordinados directos
Ejemplo - Detectar Duplicados:
-- Encontrar clientes potencialmente duplicados
SELECT
c1.id AS cliente1_id,
c1.nombre_cliente AS cliente1,
c1.email AS email1,
c1.telefono AS telefono1,
c2.id AS cliente2_id,
c2.nombre_cliente AS cliente2,
c2.email AS email2,
c2.telefono AS telefono2,
CASE
WHEN c1.email = c2.email THEN 'Email Idéntico'
WHEN c1.telefono = c2.telefono THEN 'Teléfono Idéntico'
WHEN LOWER(c1.nombre_cliente) = LOWER(c2.nombre_cliente) THEN 'Nombre Idéntico'
ELSE 'Similitud Sospechosa'
END AS tipo_duplicado,
c1.fecha_registro AS fecha_reg1,
c2.fecha_registro AS fecha_reg2
FROM clientes c1
INNER JOIN clientes c2 ON c1.id < c2.id -- Evita duplicados en el resultado
AND (
c1.email = c2.email
OR c1.telefono = c2.telefono
OR (LOWER(c1.nombre_cliente) = LOWER(c2.nombre_cliente)
AND c1.telefono = c2.telefono)
)
ORDER BY tipo_duplicado, c1.nombre_cliente;
¿Qué responde esta consulta?
- Clientes con emails o teléfonos duplicados
- Posibles registros duplicados por error
- Ayuda en limpieza y consolidación de base de datos
Ejemplo - Análisis de Compras Relacionadas:
-- ¿Qué productos se compran juntos frecuentemente?
SELECT
p1.nombre_producto AS producto_principal,
p1.categoria AS categoria1,
p2.nombre_producto AS producto_relacionado,
p2.categoria AS categoria2,
COUNT(*) AS veces_comprados_juntos,
ROUND(AVG(v.monto_total), 2) AS ticket_promedio_combinado,
ROUND(COUNT(*) * 100.0 / (
SELECT COUNT(DISTINCT venta_id)
FROM detalle_venta
WHERE producto_id = p1.id
), 2) AS porcentaje_co_ocurrencia
FROM detalle_venta dv1
INNER JOIN detalle_venta dv2 ON dv1.venta_id = dv2.venta_id
AND dv1.producto_id < dv2.producto_id -- Evita duplicados (A-B y B-A)
INNER JOIN productos p1 ON dv1.producto_id = p1.id
INNER JOIN productos p2 ON dv2.producto_id = p2.id
INNER JOIN ventas v ON dv1.venta_id = v.id
WHERE v.fecha_venta >= DATE('now', '-6 months')
GROUP BY p1.id, p1.nombre_producto, p1.categoria, p2.id, p2.nombre_producto, p2.categoria
HAVING veces_comprados_juntos >= 5
ORDER BY veces_comprados_juntos DESC, porcentaje_co_ocurrencia DESC
LIMIT 20;
¿Qué responde esta consulta?
- Productos que se compran juntos frecuentemente
- Base para sistemas de recomendación ("Los clientes que compraron X también compraron Y")
- Estrategias de cross-selling y bundling
Casos de Uso Avanzados
Caso 1: Dashboard Ejecutivo de Ventas
-- Vista consolidada de desempeño de ventas con múltiples dimensiones
WITH ventas_por_mes AS (
SELECT
strftime('%Y-%m', fecha_venta) AS mes,
vendedor_id,
SUM(monto_total) AS total_ventas,
COUNT(*) AS num_transacciones,
AVG(monto_total) AS ticket_promedio,
COUNT(DISTINCT cliente_id) AS clientes_unicos
FROM ventas
WHERE fecha_venta >= DATE('now', '-12 months')
GROUP BY mes, vendedor_id
),
metas_del_mes AS (
SELECT
vendedor_id,
strftime('%Y-%m', mes) AS mes,
meta_mensual
FROM metas
WHERE mes >= DATE('now', '-12 months')
)
SELECT
ven.nombre AS vendedor,
d.nombre_departamento AS departamento,
vm.mes,
vm.total_ventas,
vm.num_transacciones,
ROUND(vm.ticket_promedio, 2) AS ticket_promedio,
vm.clientes_unicos,
COALESCE(m.meta_mensual, 0) AS meta_mensual,
ROUND((vm.total_ventas / NULLIF(m.meta_mensual, 0)) * 100, 2) AS cumplimiento_porcentaje,
CASE
WHEN vm.total_ventas >= m.meta_mensual * 1.2 THEN ' Excelente'
WHEN vm.total_ventas >= m.meta_mensual THEN ' Cumplido'
WHEN vm.total_ventas >= m.meta_mensual * 0.8 THEN ' En Progreso'
ELSE ' Bajo Rendimiento'
END AS estado_evaluacion,
-- Comparación con mes anterior
LAG(vm.total_ventas) OVER (PARTITION BY vm.vendedor_id ORDER BY vm.mes) AS ventas_mes_anterior,
ROUND(
((vm.total_ventas - LAG(vm.total_ventas) OVER (PARTITION BY vm.vendedor_id ORDER BY vm.mes))
/ NULLIF(LAG(vm.total_ventas) OVER (PARTITION BY vm.vendedor_id ORDER BY vm.mes), 0)) * 100,
2
) AS crecimiento_porcentual,
-- Ranking dentro del departamento
RANK() OVER (PARTITION BY d.id, vm.mes ORDER BY vm.total_ventas DESC) AS ranking_departamento
FROM ventas_por_mes vm
INNER JOIN vendedores ven ON vm.vendedor_id = ven.id
INNER JOIN departamentos d ON ven.departamento_id = d.id
LEFT JOIN metas_del_mes m ON vm.vendedor_id = m.vendedor_id AND vm.mes = m.mes
WHERE ven.activo = 1
ORDER BY vm.mes DESC, vm.total_ventas DESC;
- Desempeño mensual de cada vendedor vs su meta
- Tendencias de crecimiento mes a mes
- Rankings dentro de cada departamento
- Identificación de vendedores de alto y bajo rendimiento
Caso 2: Análisis de Retención de Clientes (Análisis de Cohortes)
-- Análisis de retención por mes de primera compra
WITH primera_compra_cliente AS (
SELECT
cliente_id,
strftime('%Y-%m', MIN(fecha_venta)) AS mes_cohorte,
MIN(fecha_venta) AS fecha_primera_compra
FROM ventas
GROUP BY cliente_id
),
compras_por_mes AS (
SELECT
v.cliente_id,
strftime('%Y-%m', v.fecha_venta) AS mes_compra,
SUM(v.monto_total) AS total_gastado,
COUNT(*) AS num_compras
FROM ventas v
GROUP BY v.cliente_id, mes_compra
)
SELECT
pc.mes_cohorte AS cohorte,
COUNT(DISTINCT pc.cliente_id) AS clientes_iniciales,
cm.mes_compra AS mes_analizado,
-- Calcular meses desde primera compra
(CAST(strftime('%Y', cm.mes_compra || '-01') AS INTEGER) - CAST(strftime('%Y', pc.mes_cohorte || '-01') AS INTEGER)) * 12 +
(CAST(strftime('%m', cm.mes_compra || '-01') AS INTEGER) - CAST(strftime('%m', pc.mes_cohorte || '-01') AS INTEGER))
AS meses_desde_inicio,
COUNT(DISTINCT cm.cliente_id) AS clientes_activos_mes,
ROUND(COUNT(DISTINCT cm.cliente_id) * 100.0 / COUNT(DISTINCT pc.cliente_id), 2) AS tasa_retencion_porcentaje,
ROUND(AVG(cm.total_gastado), 2) AS gasto_promedio_mes,
SUM(cm.num_compras) AS transacciones_totales
FROM primera_compra_cliente pc
LEFT JOIN compras_por_mes cm ON pc.cliente_id = cm.cliente_id
WHERE pc.mes_cohorte >= strftime('%Y-%m', DATE('now', '-12 months'))
GROUP BY pc.mes_cohorte, cm.mes_compra
HAVING meses_desde_inicio IS NOT NULL
ORDER BY pc.mes_cohorte, meses_desde_inicio;
- Tasa de retención de clientes por cohorte mensual
- ¿Cuántos clientes regresan después de su primera compra?
- Patrones de comportamiento a lo largo del tiempo
- Identificar en qué punto los clientes abandonan
Caso 3: Análisis de Rentabilidad por Proyecto
-- Análisis completo de proyectos: rentabilidad, recursos y desempeño
SELECT
p.id AS proyecto_id,
p.nombre_proyecto,
p.estado,
p.fecha_inicio,
p.fecha_fin_estimada,
CAST((julianday(p.fecha_fin_estimada) - julianday(p.fecha_inicio)) AS INTEGER) AS duracion_dias_estimada,
CAST((julianday('now') - julianday(p.fecha_inicio)) AS INTEGER) AS dias_transcurridos,
-- Información del cliente
c.nombre_cliente,
c.segmento AS segmento_cliente,
-- Responsable del proyecto
e.nombre || ' ' || e.apellido AS responsable,
d.nombre_departamento AS departamento_responsable,
-- Métricas financieras
p.presupuesto,
COALESCE(SUM(e_asignados.salario * (t.horas_estimadas / 160)), 0) AS costo_estimado_nomina,
p.presupuesto - COALESCE(SUM(e_asignados.salario * (t.horas_estimadas / 160)), 0) AS margen_estimado,
ROUND((p.presupuesto - COALESCE(SUM(e_asignados.salario * (t.horas_estimadas / 160)), 0)) /
NULLIF(p.presupuesto, 0) * 100, 2) AS margen_porcentual,
-- Métricas de tareas
COUNT(DISTINCT t.id) AS total_tareas,
SUM(CASE WHEN t.estado = 'completada' THEN 1 ELSE 0 END) AS tareas_completadas,
SUM(CASE WHEN t.estado = 'en_progreso' THEN 1 ELSE 0 END) AS tareas_en_progreso,
SUM(CASE WHEN t.estado = 'pendiente' THEN 1 ELSE 0 END) AS tareas_pendientes,
ROUND(AVG(t.progreso), 2) AS progreso_promedio,
SUM(t.horas_estimadas) AS horas_totales_estimadas,
COUNT(DISTINCT t.asignado_a) AS empleados_asignados,
-- Análisis de cumplimiento
CASE
WHEN p.fecha_fin_estimada < DATE('now') AND p.estado != 'completado' THEN ' Retrasado'
WHEN AVG(t.progreso) < 50 AND
CAST((julianday('now') - julianday(p.fecha_inicio)) AS REAL) /
NULLIF(CAST((julianday(p.fecha_fin_estimada) - julianday(p.fecha_inicio)) AS REAL), 0) > 0.5
THEN '🟡 En Riesgo'
WHEN p.estado = 'completado' THEN '🟢 Completado'
ELSE '🟢 En Tiempo'
END AS estado_cumplimiento,
-- Salud general del proyecto
CASE
WHEN margen_estimado < 0 THEN ' Sobre Presupuesto'
WHEN margen_porcentual < 10 THEN ' Margen Bajo'
WHEN margen_porcentual >= 20 THEN ' Margen Saludable'
ELSE ' Aceptable'
END AS salud_financiera
FROM proyectos p
INNER JOIN clientes c ON p.cliente_id = c.id
INNER JOIN empleados e ON p.responsable_id = e.id
INNER JOIN departamentos d ON e.departamento_id = d.id
LEFT JOIN tareas t ON t.proyecto_id = p.id
LEFT JOIN empleados e_asignados ON t.asignado_a = e_asignados.id
WHERE p.estado IN ('activo', 'en_progreso')
GROUP BY p.id, p.nombre_proyecto, p.estado, p.fecha_inicio, p.fecha_fin_estimada,
c.nombre_cliente, c.segmento, e.nombre, e.apellido, d.nombre_departamento, p.presupuesto
HAVING progreso_promedio < 80 OR estado_cumplimiento != '🟢 En Tiempo'
ORDER BY estado_cumplimiento, margen_porcentual ASC;
- Proyectos con problemas de presupuesto o cronograma
- Rentabilidad estimada de cada proyecto
- Distribución de tareas y recursos
- Identificación temprana de proyectos en riesgo
Caso 4: Sistema de Recomendaciones y Cross-Selling
-- Productos frecuentemente comprados juntos para recomendaciones
WITH pares_productos AS (
SELECT
dv1.producto_id AS producto_principal_id,
dv2.producto_id AS producto_relacionado_id,
COUNT(DISTINCT dv1.venta_id) AS veces_juntos,
AVG(v.monto_total) AS ticket_promedio
FROM detalle_venta dv1
INNER JOIN detalle_venta dv2 ON dv1.venta_id = dv2.venta_id
AND dv1.producto_id < dv2.producto_id
INNER JOIN ventas v ON dv1.venta_id = v.id
WHERE v.fecha_venta >= DATE('now', '-6 months')
GROUP BY dv1.producto_id, dv2.producto_id
HAVING COUNT(DISTINCT dv1.venta_id) >= 3
),
ventas_individuales AS (
SELECT
producto_id,
COUNT(DISTINCT venta_id) AS veces_vendido
FROM detalle_venta dv
INNER JOIN ventas v ON dv.venta_id = v.id
WHERE v.fecha_venta >= DATE('now', '-6 months')
GROUP BY producto_id
)
SELECT
p1.nombre_producto AS producto,
p1.categoria AS categoria_principal,
p1.precio AS precio_principal,
p2.nombre_producto AS producto_recomendado,
p2.categoria AS categoria_recomendada,
p2.precio AS precio_recomendado,
pp.veces_juntos AS comprados_juntos,
vi1.veces_vendido AS ventas_producto_principal,
ROUND(pp.veces_juntos * 100.0 / vi1.veces_vendido, 2) AS porcentaje_conversion,
ROUND(pp.ticket_promedio, 2) AS ticket_promedio_combo,
ROUND((p1.precio + p2.precio) * 0.95, 2) AS precio_bundle_sugerido,
CASE
WHEN pp.veces_juntos * 100.0 / vi1.veces_vendido > 40 THEN ' Alta Afinidad'
WHEN pp.veces_juntos * 100.0 / vi1.veces_vendido > 20 THEN ' Buena Afinidad'
ELSE ' Afinidad Moderada'
END AS nivel_recomendacion
FROM pares_productos pp
INNER JOIN productos p1 ON pp.producto_principal_id = p1.id
INNER JOIN productos p2 ON pp.producto_relacionado_id = p2.id
INNER JOIN ventas_individuales vi1 ON pp.producto_principal_id = vi1.producto_id
WHERE pp.veces_juntos >= 5
ORDER BY porcentaje_conversion DESC, pp.veces_juntos DESC
LIMIT 30;
- Pares de productos con alta probabilidad de venta conjunta
- Porcentajes de conversión para estrategias de cross-selling
- Sugerencias de precios para bundles
- Base para "Los clientes que compraron X también compraron Y"
Mejores Prácticas
1. Performance y Optimización
Usa índices en columnas de JOIN
-- Índices esenciales para mejorar performance
CREATE INDEX idx_empleados_departamento ON empleados(departamento_id);
CREATE INDEX idx_empleados_supervisor ON empleados(supervisor_id);
CREATE INDEX idx_ventas_cliente_fecha ON ventas(cliente_id, fecha_venta);
CREATE INDEX idx_ventas_vendedor ON ventas(vendedor_id);
CREATE INDEX idx_detalle_producto_venta ON detalle_venta(producto_id, venta_id);
CREATE INDEX idx_tareas_proyecto_estado ON tareas(proyecto_id, estado);
Filtra temprano usando WHERE
-- MAL: JOIN primero, filtrar después (procesa más datos)
SELECT e.nombre, d.nombre_departamento
FROM empleados e
INNER JOIN departamentos d ON e.departamento_id = d.id
WHERE e.fecha_contratacion >= '2023-01-01';
-- BIEN: Filtrar antes del JOIN cuando sea posible
SELECT e.nombre, d.nombre_departamento
FROM (
SELECT * FROM empleados
WHERE fecha_contratacion >= '2023-01-01'
) e
INNER JOIN departamentos d ON e.departamento_id = d.id;
Evita SELECT * en consultas complejas
-- MAL: Trae todos los campos (más memoria y red)
SELECT *
FROM ventas v
INNER JOIN clientes c ON v.cliente_id = c.id;
-- BIEN: Solo los campos necesarios
SELECT
v.id, v.fecha_venta, v.monto_total,
c.nombre_cliente, c.email
FROM ventas v
INNER JOIN clientes c ON v.cliente_id = c.id;
Usa EXPLAIN para analizar consultas
EXPLAIN QUERY PLAN
SELECT
e.nombre,
d.nombre_departamento
FROM empleados e
INNER JOIN departamentos d ON e.departamento_id = d.id
WHERE e.activo = 1;
2. Legibilidad y Mantenibilidad
Usa alias claros y consistentes
-- MAL: Alias confusos
SELECT t1.n, t2.x
FROM empleados t1
JOIN departamentos t2 ON t1.d = t2.i;
-- BIEN: Alias descriptivos
SELECT
emp.nombre,
dept.nombre_departamento
FROM empleados emp
INNER JOIN departamentos dept ON emp.departamento_id = dept.id;
Indenta correctamente
-- BIEN: Estructura clara y fácil de leer
SELECT
p.nombre_proyecto,
c.nombre_cliente,
e.nombre AS responsable,
d.nombre_departamento
FROM proyectos p
INNER JOIN clientes c ON p.cliente_id = c.id
INNER JOIN empleados e ON p.responsable_id = e.id
INNER JOIN departamentos d ON e.departamento_id = d.id
WHERE p.estado = 'activo'
ORDER BY p.fecha_inicio DESC;
Comenta JOINs complejos
SELECT
p.nombre_proyecto,
COUNT(DISTINCT t.id) AS total_tareas
FROM proyectos p
-- Obtener todas las tareas, incluso proyectos sin tareas
LEFT JOIN tareas t ON t.proyecto_id = p.id
-- Solo tareas activas de los últimos 6 meses
AND t.fecha_vencimiento >= DATE('now', '-6 months')
AND t.estado != 'cancelada'
WHERE p.estado = 'activo'
GROUP BY p.id, p.nombre_proyecto;
Usa CTEs para consultas complejas
-- BIEN: CTEs hacen el código modular y legible
WITH ventas_recientes AS (
SELECT
cliente_id,
SUM(monto_total) AS total_gastado,
COUNT(*) AS num_compras
FROM ventas
WHERE fecha_venta >= DATE('now', '-1 year')
GROUP BY cliente_id
),
clientes_premium AS (
SELECT cliente_id
FROM ventas_recientes
WHERE total_gastado > 10000
)
SELECT
c.nombre_cliente,
vr.total_gastado,
vr.num_compras
FROM clientes c
INNER JOIN ventas_recientes vr ON c.id = vr.cliente_id
INNER JOIN clientes_premium cp ON c.id = cp.cliente_id
ORDER BY vr.total_gastado DESC;
3. Evitar Errores Comunes
Error: Multiplicación de filas en múltiples JOINs
-- PROBLEMA: Esto puede duplicar resultados
SELECT
p.nombre_proyecto,
COUNT(*) AS total -- ¿Total de qué exactamente?
FROM proyectos p
LEFT JOIN tareas t ON t.proyecto_id = p.id
LEFT JOIN empleados e ON e.id = t.asignado_a
GROUP BY p.id, p.nombre_proyecto;
-- SOLUCIÓN: Usa DISTINCT o subconsultas
SELECT
p.nombre_proyecto,
COUNT(DISTINCT t.id) AS total_tareas,
COUNT(DISTINCT e.id) AS total_empleados
FROM proyectos p
LEFT JOIN tareas t ON t.proyecto_id = p.id
LEFT JOIN empleados e ON e.id = t.asignado_a
GROUP BY p.id, p.nombre_proyecto;
Error: Comparar NULL con operadores normales
-- MAL: NULL != 'algo' siempre es NULL (ni TRUE ni FALSE)
SELECT *
FROM empleados e
LEFT JOIN departamentos d ON e.departamento_id = d.id
WHERE d.nombre_departamento != 'Ventas';
-- BIEN: Maneja NULL explícitamente
SELECT *
FROM empleados e
LEFT JOIN departamentos d ON e.departamento_id = d.id
WHERE d.nombre_departamento != 'Ventas'
OR d.nombre_departamento IS NULL;
Error: No usar COALESCE para valores predeterminados
-- MAL: NULL en cálculos da NULL
SELECT
c.nombre_cliente,
SUM(v.monto_total) AS total_ventas -- Será NULL si no hay ventas
FROM clientes c
LEFT JOIN ventas v ON c.id = v.cliente_id
GROUP BY c.id, c.nombre_cliente;
-- BIEN: Usa COALESCE para valores predeterminados
SELECT
c.nombre_cliente,
COALESCE(SUM(v.monto_total), 0) AS total_ventas
FROM clientes c
LEFT JOIN ventas v ON c.id = v.cliente_id
GROUP BY c.id, c.nombre_cliente;
Preguntas Frecuentes sobre JOINs
¿Cuál es la diferencia entre INNER JOIN y WHERE?
-- Estos dos son equivalentes en resultado:
-- Forma 1: INNER JOIN explícito (RECOMENDADO)
SELECT e.nombre, d.nombre_departamento
FROM empleados e
INNER JOIN departamentos d ON e.departamento_id = d.id;
-- Forma 2: JOIN implícito con WHERE (estilo antiguo)
SELECT e.nombre, d.nombre_departamento
FROM empleados e, departamentos d
WHERE e.departamento_id = d.id;
Recomendación: Usa siempre INNER JOIN explícito. Es más legible y menos propenso a errores.
¿Qué pasa si hago JOIN sin condición?
-- Esto es un CROSS JOIN implícito (producto cartesiano)
SELECT *
FROM empleados e
INNER JOIN departamentos d; -- ¡FALTA ON!
-- Si tienes 100 empleados y 5 departamentos, obtendrás 500 filas
¿Puedo hacer JOIN con más de 2 tablas?
-- Sí, puedes encadenar tantos JOINs como necesites
SELECT
v.id,
c.nombre_cliente,
p.nombre_producto,
ven.nombre AS vendedor,
d.nombre_departamento
FROM ventas v
INNER JOIN clientes c ON v.cliente_id = c.id
INNER JOIN detalle_venta dv ON v.id = dv.venta_id
INNER JOIN productos p ON dv.producto_id = p.id
INNER JOIN vendedores ven ON v.vendedor_id = ven.id
INNER JOIN departamentos d ON ven.departamento_id = d.id;
Recomendación: Si necesitas más de 5-6 JOINs, considera crear vistas o dividir en subconsultas.
¿LEFT JOIN vs LEFT OUTER JOIN?
-- Son exactamente lo mismo
SELECT * FROM empleados e
LEFT JOIN departamentos d ON e.departamento_id = d.id;
-- Es equivalente a:
SELECT * FROM empleados e
LEFT OUTER JOIN departamentos d ON e.departamento_id = d.id;
La palabra OUTER es opcional. La mayoría de desarrolladores usa simplemente LEFT JOIN.
¿Cómo optimizo una consulta con muchos JOINs?
- Crea índices en las columnas de JOIN
- Filtra temprano con WHERE
- Usa EXPLAIN para ver el plan de ejecución
- Limita las columnas con SELECT específico
- Considera vistas materializadas para consultas frecuentes
Tabla Comparativa Rápida
| Tipo | Retorna | Uso Principal | Performance | SQLite |
|---|---|---|---|---|
| INNER JOIN | Solo coincidencias | Relaciones obligatorias | Rápido | Sí |
| LEFT JOIN | Todo izquierda + coincidencias | Incluir registros sin relación | Medio | Sí |
| RIGHT JOIN | Todo derecha + coincidencias | Raramente usado | Medio | No (usar LEFT) |
| FULL OUTER JOIN | Todo de ambas | Análisis de discrepancias | Lento | No (simular con UNION) |
| CROSS JOIN | Producto cartesiano | Generar combinaciones | Muy lento | Sí |
| SELF JOIN | Tabla consigo misma | Jerarquías | Medio | Sí |
On this page